♦ 删除所有行首的空格:
:%s/^□□*\(.*\)/\1/
其中,使用^□□*查找行首的一个或多个空格;而\(.*\)将行中的其它内容捕获为组;在替换部分使用\1来恢复捕获组。
♦ 删除所有行尾的空格:
:%s/\(.*\)□□*$/\1/
其中,使用□□*$查找行尾的一个或多个空格;而\(.*\)将行中的其它内容捕获为组;在替换部分使用\1来恢复捕获组。
♦ 将多个空格替换为一个空格:
:%s/□□*/□/g
其中,第一个□代表一个实际的空格,而□*则会匹配零个或多个空格。
♦ 将冒号或句点之后的多个空格,替换为一个空格:
:%s/\([:.]\)□□*/\1□/g
其中,方括号内的的特殊字符(比如.)并不需要转义。
请在实际使用以上命令时,将其中“□”的替换为空格“ ”。
♦ 如果想要查找的内容之中包含换行符,那么可以使用"\n"通配符。执行以下命令,将匹配以"the"结尾的行,和以"word"开头的下一行:
/the\nword
♦ 如果希望同时匹配包含换行,以及不包含换行(但包含一个空格)的"the word",那么可以使用"\_s"匹配空格或换行:
/the\_sword
♦ 如果希望同时匹配包含多个空格以及换行的"the word",那么可以使用"+"通配符来匹配一次或多次:
/the\_s\+word
关于删除换行和空行,请参阅换行(Line Feed)章节。
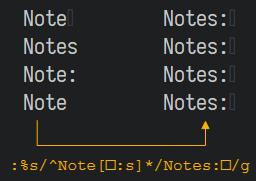
♦ 将单数单词,替换为复数:
:%s/^Note[□:s]*/Notes:□/g
其中,"Note[□:s]"将匹配"Note□","Notes", 和"Note:";而星号则会匹配零个后缀,即"Note"。
♦ 匹配引号包围的字符串(包含换行):
"\_[^"]*"
♦ 匹配特定单词包围的字符串(包含换行):
\(we\).*\1
其中,"\(we\)"将指定单词捕获为组,然后使用"\1"反向引用捕获组,以定义字符串的边界。

关于捕获组的详细介绍,请参阅捕获组(Groups)章节。
♦ 删除下图中黄色高亮区域,即行头以点分隔的章节号:
:%s/^[1-9][0-9]*\.[1-9][0-9.]*□//
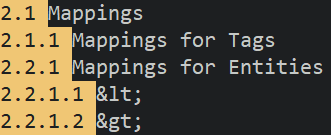
其中,模式末尾的"[0-9.]*"可以继续匹配更多层级的章节号。
♦ 匹配最少3个字符,最多16个字符,由字母和数字组成的用户名:
^[a-zA-Z0-9_-]{3,16}$
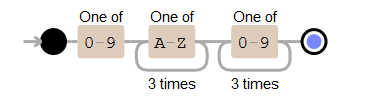
♦ 查找类似“1MGU103”的序列号。即由1个数字,3个大写字符和3个数字组成的字符串。可以使用以下几种不同的模式:
[0-9][A-Z]{3}[0-9]{3}
\d\u{3}\d{3}
\d\u\u\u\d\d\d
[[:digit:]][[:upper:]]{3}[[:digit:]]{3}
其中:
请注意,以上表达式均采用Very Magic模式。
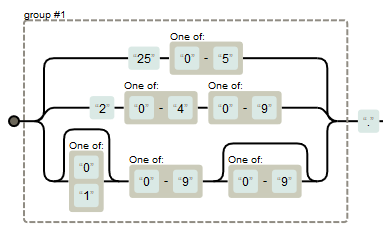
♦ 匹配IPv4网络地址。即从"0.0.0.0"到"999.999.999.999"范围内的,以点分割的四段数字。
/\v([0-9]{1,3}[\.]){3}[0-9]{1,3}
但是以上命令,并不会判断数字串是否是一个有效的IP地址。比如"256.60.124.136"也会被匹配。但有效的IP地址中,每段数字均应为"0-255"。
♦ 匹配有效的IP地址。
/\v(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)
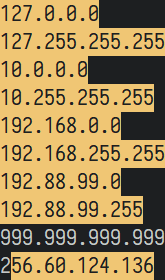
以上表达式分为四段重复的捕获组,每组数字的范围如下图所示: