Vim使用正则表达式(regular expressions)来进行逻辑查找。正则达式是神秘和简洁的,然而这种强大的功能也必须要以大量的学习才能够习惯和掌握。
一个正则表达式是由一些元素组成的,一个元素可以是一个字符或者是一个特殊字符。
以下表格列示了常用的简单元素:
x | 字符x |
^ | 一行的开始处 |
$ | 一行的结尾处 |
. | 任意单个字符 |
< | 开始标记 |
> | 结尾标记 |
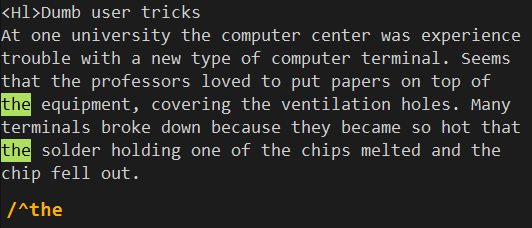
^acme,将匹配以acme开始的行。注意:除非出现在模式的开头,否则音调符号^就不是一个代表行开头的通配符,而会代表其他的含义。2^4,将匹配包含"2^4"的所有行。如果要查找以“^”开头的行,则需要使用^^模式。其中第一个^是通配符用于指示一行的开头,而第二个^则是实际的音调符号。如果要指明前导^是一个实际的音调符号而不是表示一行开头的通配符,那么就需要在其前面加一个转义的反斜杠“\”来组成\^acme模式。
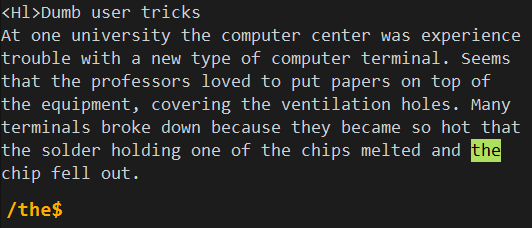
acme$,将匹配以acme结尾的行。^acme$,将匹配只包含acme一个单词的行。而^$,则会匹配所有空行。
dog.bone,将匹配dog-bone,dog bone,dog/bone,但不会匹配dogbone,因为dog和bone之间并没有分隔符。
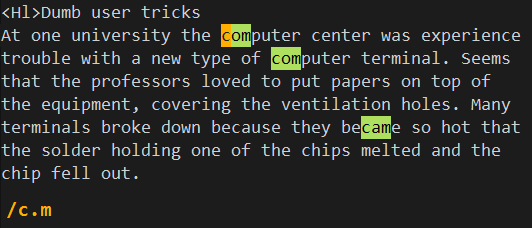
要指示任何字符出现的次数,可以同时使用句点和星号(.*),例如dog.*bone将匹配以下字符串(但不会匹配dog在一行而bone在另一行的情况):
dogbone
dog-bone
doggy bone
My dog has a bone
\<用于匹配一个单词的开始。比如/\<f命令,可以查找所有以“f”开头的单词。
\>用于匹配一个单词的结束。比如/f\>命令,可以查找所有以“f”结尾的单词。
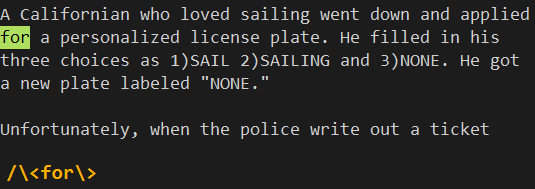
也就是说,只要将想要查找的字符串包围其中,就可以实现精确查找。例如在文件中有单词Californian和Unfortunately。如果使用命令/for来查找,那么也会找到这两个单词。
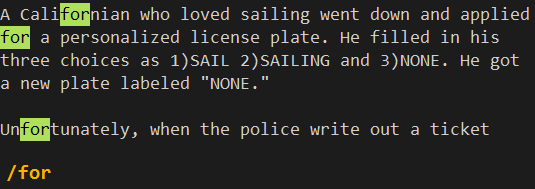
如果使用表达式/\<for\>来进行查找,则只会精确的查找到for,而不会出现其他的匹配。
星号(*)通配符,作用于其之前的一个元素,表示可以匹配0次或是多次。表达式的贪婪(greedy)特性,将尝试查找尽可能多的匹配项。te*将会匹配te,tee,teee等等。甚至还会匹配t,因为在这里e可以出现0次。

加号(+)通配符,表示一个字符可以匹配一次或是多次。所以表达式te\+可以匹配te,tee,teee等等。但是不会再匹配t,因为这里e最少要出现一次。

等号(=)和问号(?)通配符,表示一个字符匹配0次或是一次。所以表达te\=可以匹配t和te,但是不会匹配tee,因为这个表达式只能匹配不多于两个字符。
